The Data Layer Beneath Intelligent AI Delegation
Google DeepMind researchers just published the requirements for safe AI delegation. The data infrastructure to meet them already exists.

Four days ago, Google DeepMind released a paper called “Intelligent AI Delegation” (Tomasev, Franklin, and Osindero, 2026). It is one of the most important papers published this year on the agentic web, and I suspect most people building AI agents have not yet read it.
The paper proposes a framework for how AI agents should decompose tasks, delegate them to other agents or humans, and maintain accountability across complex delegation chains. It identifies five requirements that any intelligent delegation framework must satisfy: dynamic assessment, adaptive execution, structural transparency, scalable market coordination, and systemic resilience.
I read it with a growing sense of recognition. Not because the ideas were familiar in the way that recycled ideas are familiar. Because the problems they describe at the agent coordination layer are precisely the problems we have been engineering solutions for at the data layer.
Here is the thing: the paper does not address it, because it is not the paper’s job to address it. Every one of those five requirements presupposes a data infrastructure that does not yet exist in most systems. The DeepMind team is designing the delegation protocol. What sits underneath the protocol, the data that agents actually exchange, verify, and trust, is an open question.
I think we have an answer.
The Five Requirements and Their Data Prerequisites
1. Dynamic Assessment
The paper argues that delegation requires “granular inference of agent state” (Section 4, Table 1). Before delegating a task, the delegator must evaluate complexity, criticality, uncertainty, cost, resource requirements, constraints, verifiability, reversibility, contextuality, and subjectivity (Section 2.2). This is not a one-time evaluation. It runs continuously, updating beliefs about each agent’s likelihood of success, expected duration, and cost.
Here is the data problem embedded in that requirement: the assessment is only as good as the metadata attached to the task and its outputs. If a delegated task produces a dataset, how does the delegator assess whether the output conforms to the specification? If the specification lives in a README, a Slack message, or the system prompt of another agent, the assessment is inherently fragile. It depends on the delegator maintaining an accurate mental model of what was asked for.
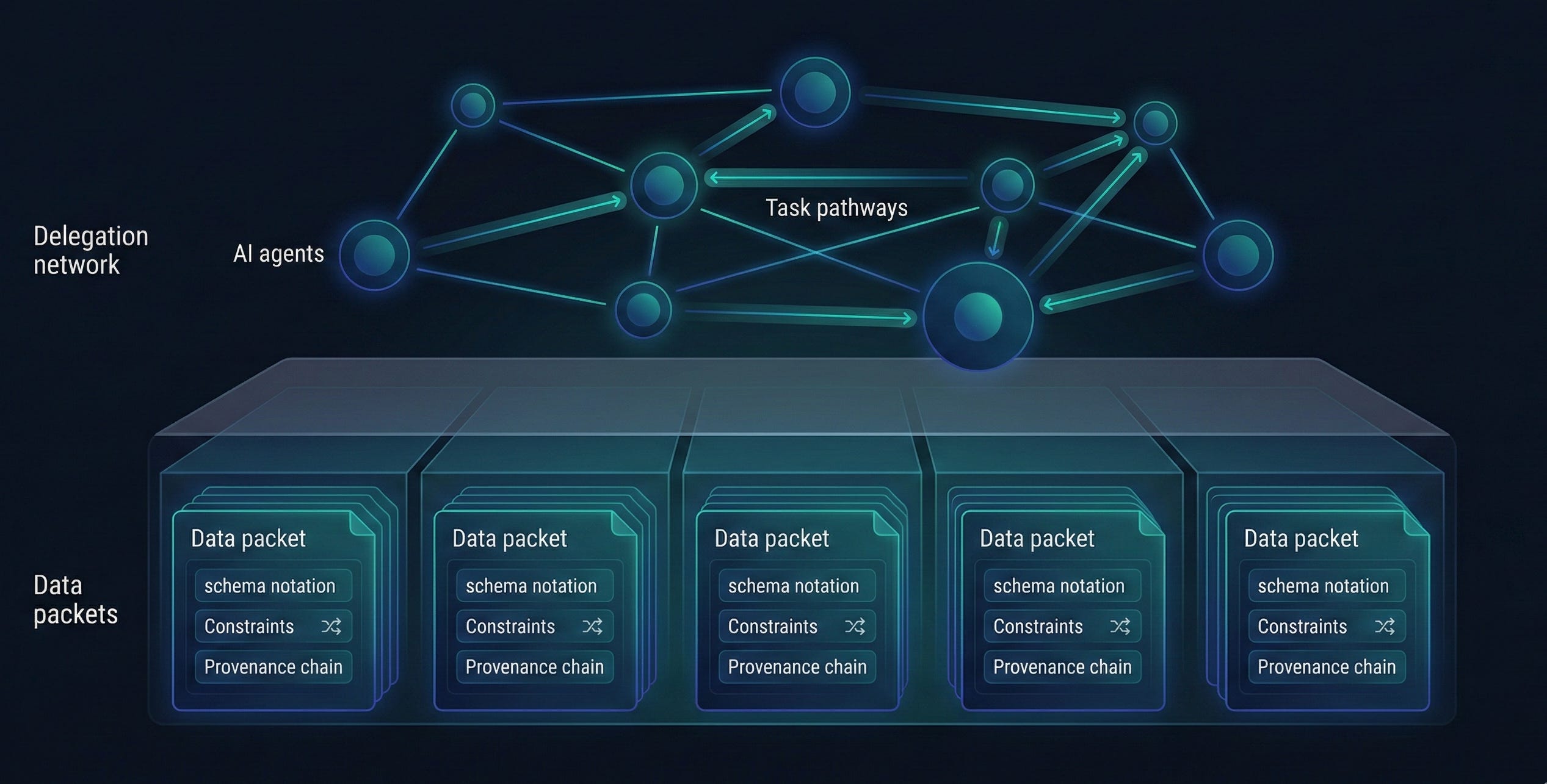
SDC4 data packets include their specification. The XSD schema defines structural constraints. SHACL shapes define validation rules. RDF annotations define semantic meaning. When an agent receives an SDC4 output, it does not need to consult an external specification to assess conformance. The specification IS the data. Dynamic assessment becomes schema validation, which is deterministic and automatable.
2. Adaptive Execution
The paper describes adaptive coordination (Section 4.4) as the ability to respond to runtime contingencies, both external triggers (task changes, resource shifts, priority changes, security alerts) and internal triggers (performance degradation, budget overruns, verification failures, unresponsive delegatees). The delegation framework must support mid-execution switching between agents.
The data problem: when you switch delegates mid-task, the intermediate outputs must be interpretable by the new agent without the original agent’s context. Most data today is opaque. It requires understanding the producing system’s documentation, its API reference, and its internal conventions. Hand a CSV from one agent to another, and you have transferred bytes, not meaning.
SDC4’s self-describing architecture solves this directly. Every data element carries its type constraints, units, semantic links, and provenance. An XdQuantity does not just carry “42.5”. It carries the unit (kg), the magnitude range (0.0 to 500.0), the error tolerance, and the semantic annotation linking it to a specific ontology concept. A replacement agent receiving this output can resume work without any context transfer protocol. The context is in the data.

3. Structural Transparency
This is where the paper’s argument and SDC’s architecture align most precisely.
The paper states: “Current sub-task execution in AI-AI delegation is too opaque to support robust oversight for intelligent task delegation. This opacity obscures the distinction between incompetence and malice, compounding risks of collusion and chained failures” (Section 4).
They propose two solutions: monitoring (Section 4.5) and verifiable task completion (Section 4.8). Monitoring ranges from lightweight (outcome-level, black-box) to intensive (process-level, white-box). Verifiable task completion requires that provisional outcomes be validated and finalized through formal mechanisms.
The paper describes four monitoring dimensions (Table 2): target (outcome vs. process level), observability (direct vs. indirect), transparency (black-box vs. white-box), and privacy (full transparency vs. cryptographic). And crucially, a fifth dimension: topology, where they introduce the concept of “transitive accountability via attestation.” Agent B monitors Agent C, signs a summary report of C’s performance, and forwards it to Agent A. Trust propagates through signed attestations rather than direct observation.
SDC4 has an attestation model. It is not an analogy. It is a first-class component in the data architecture. Every SDC4 data model can carry an Attestation component that records who (or what) validated the data, when, and under what authority. The Participation model tracks subject, provider, and workflow roles. The provenance chain is encoded in the data itself, in W3C PROV-compatible formats, queryable via SPARQL.
When the DeepMind paper says, “the development of standardized observability protocols is critical for ensuring interoperability in the agentic web” (p. 15), they are describing a protocol layer. SDC4 provides the data layer on which the protocol sits. You cannot have standardized observability if the data being observed is not itself standardized and self-describing.
4. Scalable Market Coordination
The paper advocates for decentralized market hubs where “delegators advertise tasks and agents (or humans) can offer their services and submit competitive bids” (Section 4.2). Successful matching gets formalized into smart contracts. Trust and reputation mechanisms (Section 4.6) provide the foundation for scalable delegation.
Their reputation model (Table 3) includes three approaches: immutable ledger (verifiable transaction history), web of trust (signed credentials attesting to capabilities), and behavioral metrics (transparency and safety scores from execution analysis).
The data problem here is interoperability at scale. A decentralized market only works if the task specifications, output formats, and verification criteria are mutually intelligible among agents who have never previously interacted. This is the classic interoperability problem, and it is exactly the problem that self-describing data was designed to solve.
SDC4 schemas are portable, self-contained, and based entirely on W3C standards. An agent in one market can produce an XSD-validated, RDF-annotated, SHACL-constrained output that any other agent in any other market can validate without prior coordination. The schema does not reference an external service. It does not require API access to the producing agent. It does not depend on a shared platform. The contract is in the data.
This maps directly to the paper’s “contract-first decomposition” principle (Section 4.1): task delegation should be contingent on the outcome being verifiable. SDC4 schemas make outcomes verifiable by construction because the verification rules travel with the data.
5. Systemic Resilience
The paper’s security analysis (Section 4.9) catalogs threats from both malicious delegatees (data exfiltration, data poisoning, verification subversion, backdoor implanting) and malicious delegators (harmful task delegation, vulnerability probing). Their core observation: “the full attack surface surpasses that of any individual component, due to emergent multi-agent dynamics, risking cascading failures.”
Permission handling (Section 4.7) must implement privilege attenuation: when an agent sub-delegates, it cannot transmit its full authority; only the minimum subset required for the sub-task may be transmitted. Permissions must be “semantic constraints, where access is defined not just by the tool or dataset, but by the specific allowable operations.”
This is precisely how SDC4’s constraint system works. An XdString with a regex pattern restriction cannot accept data outside that pattern, regardless of what agent produces it. An XdQuantity with magnitude bounds rejects out-of-range values at the schema level. These are not application-layer validations that can be bypassed. They are structural constraints in XSD, enforced by any conformant parser. The data constrains itself.
The Semantic Ledger adds another layer of resilience. SDC4 implements non-destructive versioning: old definitions remain valid, new definitions coexist alongside them. No migration can corrupt historical data. There is no update that overwrites provenance. In a delegation chain where Agent A’s output feeds Agent B’s input feeds Agent C’s output, the full lineage is preserved in the data itself. If C’s output is poisoned, the chain of provenance makes it traceable.
What the Paper Assumes but Does Not Build
The DeepMind paper is a framework paper. It defines requirements, categorizes approaches, and maps the design space. It does not specify an implementation. And it should not. That is not its purpose.
But embedded in every requirement is an assumption about the data layer: that task specifications will be machine-readable, that outputs will be verifiable against contracts, that provenance will be traceable across delegation chains, that schemas will be portable across agents who have never previously interacted.
These are not trivial assumptions. Most data in production today fails to satisfy any of them. JSON blobs with ad hoc schemas. CSV files with implicit types. API responses whose structure is documented in a Notion page that may or may not be current.
The agentic web the DeepMind team envisions requires a different kind of data. Data that describes itself. Data that carries its own constraints. Data that embeds its own provenance. Data that can be verified without consulting the system that produced it.
This is not a feature request. It is an architectural prerequisite. And it is what we have been building.
The Convergence
I have been working on self-describing data architectures since before LLMs existed. The Semantic Data Charter began as a solution to healthcare interoperability, where the cost of opaque, vendor-locked data is measured in clinical errors and integration failures. The problem was never specific to healthcare. It was always about the gap between data that needs external context to be understood and data that carries its own meaning.
The agentic web is about to make that gap existentially important.
When a human analyst receives ambiguous data, they email the producer, check the documentation, or make reasonable assumptions based on domain expertise. When an AI agent receives ambiguous data at scale, across a three-layer-deep delegation chain with a smart contract enforcing a deadline and a reputation score on the line, ambiguity becomes a systemic risk.
The DeepMind paper names this risk clearly: “As delegation chains lengthen (A -> B -> C), a broad zone of indifference allows subtle intent mismatches or context-dependent harms to propagate rapidly downstream, with each agent acting as an unthinking router rather than a responsible actor” (Section 2.3, p.5).
Self-describing data does not make agents smarter. It makes the data they exchange unambiguous. It eliminates the class of errors that arise from misinterpreted schemas, missing constraints, and lost provenance. It turns the verification step from a bespoke integration project into a schema validation call.
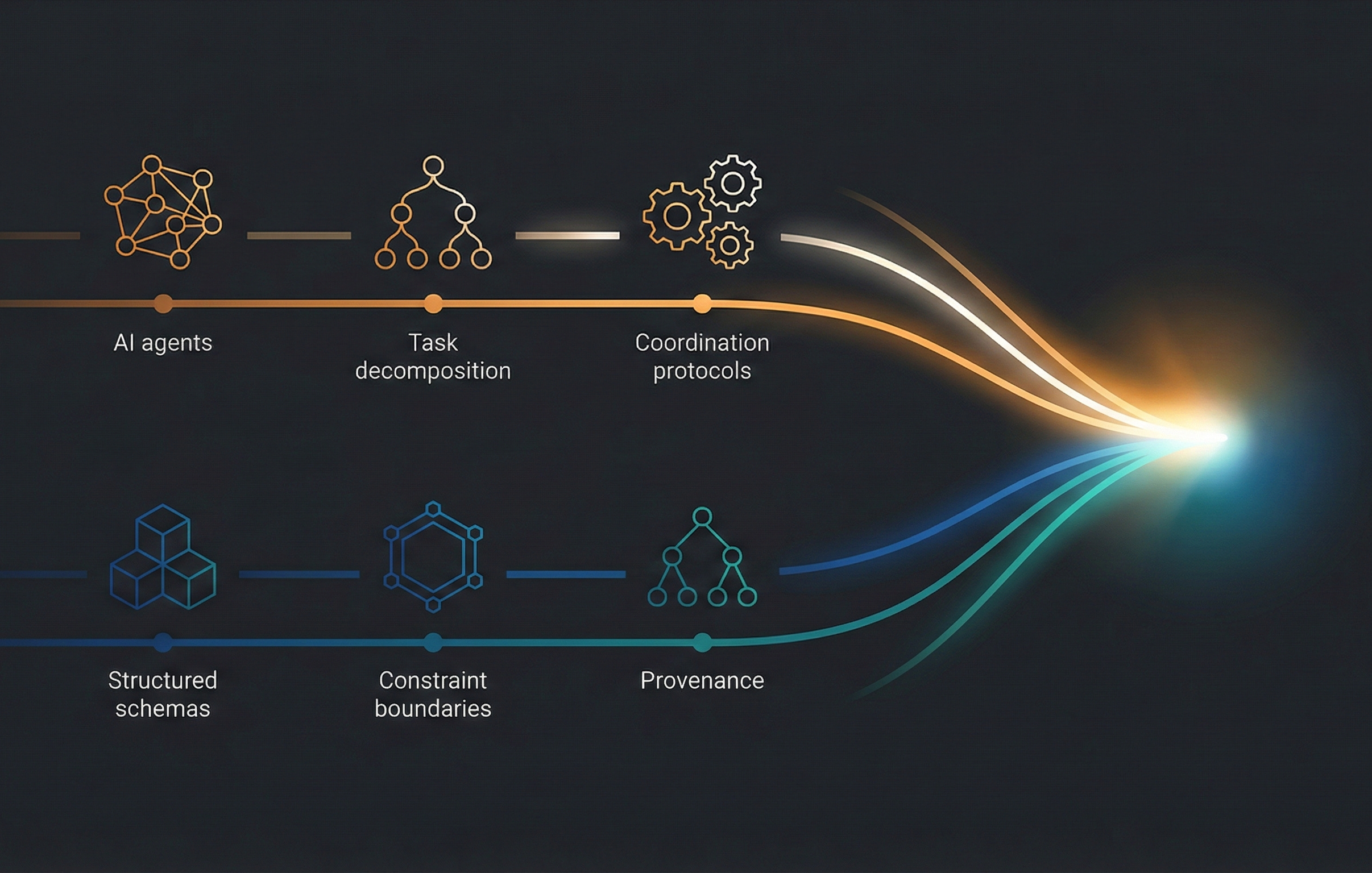
The DeepMind team has mapped the territory. The five pillars of their framework, dynamic assessment, adaptive execution, structural transparency, scalable market coordination, and systemic resilience, are the right categories. The technical protocols they describe (smart contracts, reputation ledgers, cryptographic proofs, adaptive coordination cycles) are the right mechanisms.
What goes inside those protocols, the actual data that agents produce, exchange, verify, and trust, needs to be self-describing, self-constraining, and self-documenting. That is what SDC4 provides.
SDC4 does not solve intelligent delegation. It solves the data interchange problem that intelligent delegation cannot work without. The smart contracts, the reputation ledgers, the cryptographic verification, the market coordination protocols — those are separate layers that remain to be built and integrated. SDC4 is one piece of a stack that does not yet fully exist.
But it is the foundational piece. The framework and the data layer were designed independently for the same reason: because systems that delegate authority need contracts they can trust. The DeepMind paper builds the delegation framework. SDC builds the data contracts.
They were always going to converge.
The Intelligent AI Delegation paper by Tomasev, Franklin, and Osindero (Google DeepMind, 2026) is available on arXiv.
About Axius SDC, Inc.: We build semantic data governance infrastructure. The Semantic Data Charter (SDC4) specification is open and available at semanticdatacharter.com. SDCStudio, our tooling platform for building SDC4-compliant data models, is in public beta.